

Measuring Cohesion and Coupling in Python Codebases: Practical Metrics, KPIs, and an Implementation Plan
Course: CSC-285 Systems Analysis Notes and Research
Abstract
Cohesion and coupling are widely used design-quality concepts: high cohesion indicates that a module’s responsibilities are tightly related, while low coupling indicates minimal interdependence among modules. In practice, these concepts can be operationalized with static code metrics that approximate (a) how strongly elements within a class/module relate to one another and (b) how many—and how intense—dependencies are across classes/modules. This paper proposes a pragmatic measurement approach for Python projects using established object-oriented metric definitions (e.g., LCOM and CBO), dependency-graph measures, and report-oriented KPIs that can be tracked over time to guide refactoring and architecture governance.
Introduction
Course material frames the goal as high cohesion (single, focused purpose) and loose coupling (minimal reliance on internal logic of other modules), because these properties generally reduce change risk and maintenance effort. metricssuiteforo00chid To move from concept to practice, teams need (a) measurable proxies, (b) consistent thresholds and KPIs, and (c) tooling that produces actionable reports pinpointing hotspots in real code.
Background and Metric Definitions
Cohesion (within-module relatedness)
A common operational approach is to measure cohesion at the class level using “method relatedness” via shared state. The Chidamber and Kemerer (C&K) metrics suite defines LCOM (Lack of Cohesion in Methods) in terms of method pairs that do or do not share instance variables, producing a numeric indicator of low cohesion when many method pairs do not share state. Briand'99 abstracts
Practical interpretation for Python:
Treat
self.<attribute>references inside methods as “instance-variable usage.”Compute LCOM variants per class.
Flag classes with many disconnected method groups as “multiple responsibilities” candidates.
Coupling (inter-module interdependence)
The same C&K suite defines CBO (Coupling Between Objects) as a count of how many classes a class is coupled to (through attribute types, method calls, etc.), used as a proxy for interdependence. Briand'99
Because coupling has multiple valid interpretations (imports, call edges, shared data structures), Briand and colleagues emphasize evaluating coupling measures against desirable measurement properties (e.g., capturing interdependence meaningfully and consistently). 1027092.1027094
Practical interpretation for Python:
Use import-based coupling for a reliable baseline (module dependency graph).
Add a second signal for cross-module call edges (approximate via AST inspection of calls through imported names).
Report coupling at module/package levels as well as class levels where possible.
What to Measure in a Python Codebase
Cohesion metrics (recommended minimum set)
LCOM (CK-style) per class (based on shared
self.*attributes). Briand'99 abstractsLCOM4-style components (pragmatic variant): number of connected components in a graph of methods, where edges exist when methods share
self.*attributes or call each other. (Commonly used in practice as an interpretable “how many responsibilities?” proxy.)TCC (Tight Class Cohesion, pragmatic): fraction of method pairs sharing at least one instance attribute (0–1).
Coupling metrics (recommended minimum set)
Efferent coupling (Ce): how many internal modules a module depends on (outgoing dependencies).
Afferent coupling (Ca): how many internal modules depend on a module (incoming dependencies).
Instability:
Ce / (Ca + Ce)as a directional indicator (higher ≈ more likely to ripple changes).Cross-module call edges (approx.): count of calls made through imported module aliases or imported functions.
KPI Design (Dashboards That Engineers Will Actually Use)
Cohesion KPIs
% of classes with LCOM4 = 1 (target: increase over time).
Bottom 10 cohesion-score classes (review list).
Cohesion distribution trend (median, p90) by release/sprint.
Coupling KPIs
Top 10 modules by Ce (most outward dependencies).
Top 10 modules by instability (likely refactor targets).
Dependency density: edges / possible edges in the internal dependency graph.
“Hotspot” KPI (most actionable)
Create a composite list:
High coupling module (top decile Ce or instability) AND
Contains low cohesion classes (bottom decile cohesion score)
These are typically the best refactoring candidates because they both “do too much” and “touch too much.”
Tooling Options and Libraries
Use existing tools where they fit
Radon provides maintainability index, cyclomatic complexity, and Halstead metrics—useful context signals for “too big/complex” hotspots alongside coupling/cohesion.
pydeps generates Python module dependency graphs—useful for coupling visualization and validating your import graph.
pyan3 generates approximate call graphs—useful for cross-module call-edge visualization.
There are also small tools focused specifically on Python cohesion/LCOM-style cohesion measurement (useful as benchmarks for your own implementation).
Why still implement your own analyzer?
Most general-purpose tools emphasize complexity and style. Your assignment/use case needs:
Per-class cohesion metrics grounded in your chosen definition (LCOM/LCOM4) Briand'99 abstracts
Project-scoped coupling metrics that respect “internal vs external” dependencies
Custom KPIs and charts matched to your curriculum and engineering goals
Game Plan for Implementation (Practical, Repeatable)
Phase 1 — Define scope and measurement rules (1–2 hours)
Decide what “internal modules” means (e.g., everything under
src/or a package root).Exclude noise paths (
venv/,.git/,tests/optionally).Choose your baseline metrics set (recommended minimum sets above).
Set initial thresholds as review triggers, not hard gates.
Phase 2 — Build the static analyzer (half day)
Parse
.pyfiles with Python’sast.For each class:
list methods
for each method: collect
self.<attr>usages andself.<method>()callscompute LCOM, LCOM4 components, TCC
For each module:
collect imports
build internal import graph → Ca/Ce/instability
Output machine-readable artifacts: JSON + CSV.
Phase 3 — Reporting and charts (2–4 hours)
Bar chart: worst cohesion classes (lowest score).
Bar chart: worst coupling modules (lowest score or highest Ce).
Dependency matrix heatmap (internal imports).
Optional: export GraphViz
.dotfor the import graph.
Phase 4 — Operationalize (ongoing)
Run on every PR (CI job) and on every release tag.
Store KPI snapshots (e.g., commit SHA → JSON).
Track trends (median cohesion score, p90 Ce, dependency density).
Refactor iteratively: pick the top hotspot each sprint.
Phase 5 — Validate usefulness (lightweight, but important)
Coupling/cohesion measures should be treated as indicators, and Briand et al.’s framing is useful here: ensure your chosen measures behave consistently and support the design interpretation you intend. 1027092.1027094 In practice: spot-check a few flagged classes/modules with human review and confirm the metric is catching real design issues.
References
Briand, L. C., Morasca, S., & Basili, V. R. (1999). [Coupling measurement framework / coupling properties paper]. 1027092.1027094
Chidamber, S. R., & Kemerer, C. F. (1994). A metrics suite for object-oriented design. Briand'99
Chidamber, S. R., & Kemerer, C. F. (1994). Toward a metrics suite for object-oriented design. abstracts
CSC-285 course notes. (n.d.). Cohesion and coupling. metricssuiteforo00chid
Kramer, S., & Kaindl, H. (2004). Coupling and cohesion metrics for knowledge-based systems using frames and rules. 1027092.1027094
Pyan3 contributors. (n.d.). Pyan3: Static call graph generator for Python.
Radon contributors. (n.d.). Radon documentation: Introduction to code metrics.
Thebjorn contributors. (n.d.). pydeps: Python module dependency graphs.
Tool authors. (n.d.). Cohesion measurement tools for Python (cohesion / lcom packages).
Appendix A. Cohesion and Coupling Results (Function-Based Cohesion)
Purpose and scope
This appendix interprets the cohesion/coupling results from a static analysis run of a Python codebase. The design goal is high cohesion (each module focuses on a small, related set of responsibilities) and low coupling (modules minimize dependencies), because these attributes are associated with reduced maintenance effort and change risk (Tilley, 2025). Coupling measurement has a substantial research base and is commonly treated as an indicator tied to understandability and maintainability outcomes (Briand et al., 1999).
Redaction note: Repository path details and full file paths are omitted. Module names shown match the report outputs.
Run summary (high-level KPIs)
At a high level, the run indicates low internal import coupling overall, with a small number of “hub-like” internal dependencies (especially the pipeline module), and mixed cohesion, where a handful of modules show evidence of multiple responsibilities or disconnected function clusters.
Key KPI interpretations:
Coupling: A high median coupling score indicates most modules have few internal dependencies (good—loosely coupled).
Function-based cohesion: A mid-range median function-cohesion score suggests many modules are reasonably focused, but several modules have “split” internal structure (multiple function clusters).
Interpreting the charts
Chart 1. “Lowest function-based module cohesion (heuristic)”
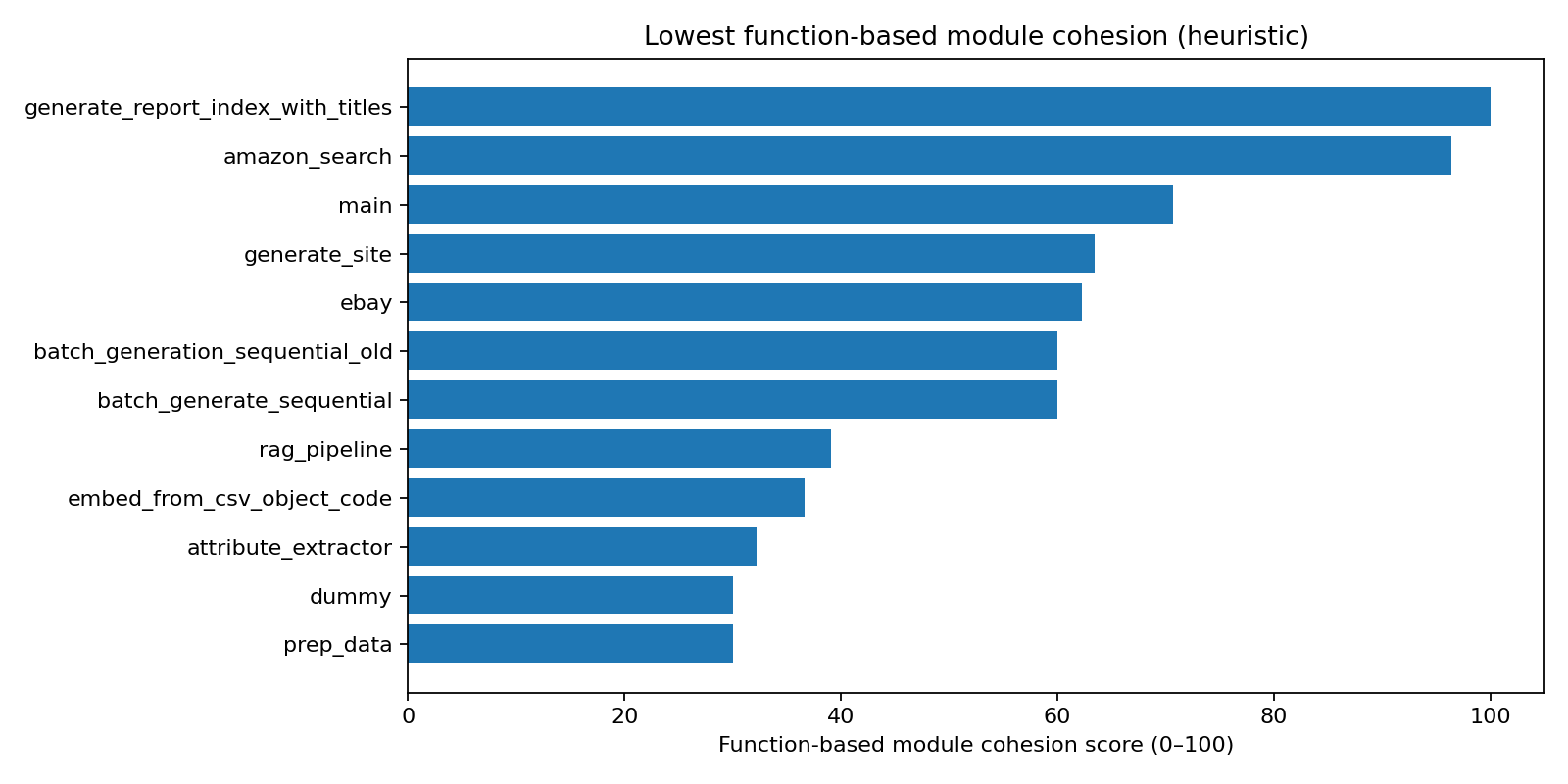
This chart highlights the modules with the weakest within-module unity based on function relationships. In this tool, low function cohesion tends to occur when:
Functions form multiple disconnected call clusters (components > 1), meaning the module behaves like two (or more) mini-modules, and/or
Functions frequently touch module-level global state, which often correlates with mixed responsibilities and reduced testability.
Important reading note: Modules with only 1 function will often score artificially high (because there is no internal structure to fragment). Treat those as “not enough evidence,” not necessarily “excellent cohesion.”
Chart 2. “Lowest coupling scores (more interdependent)”
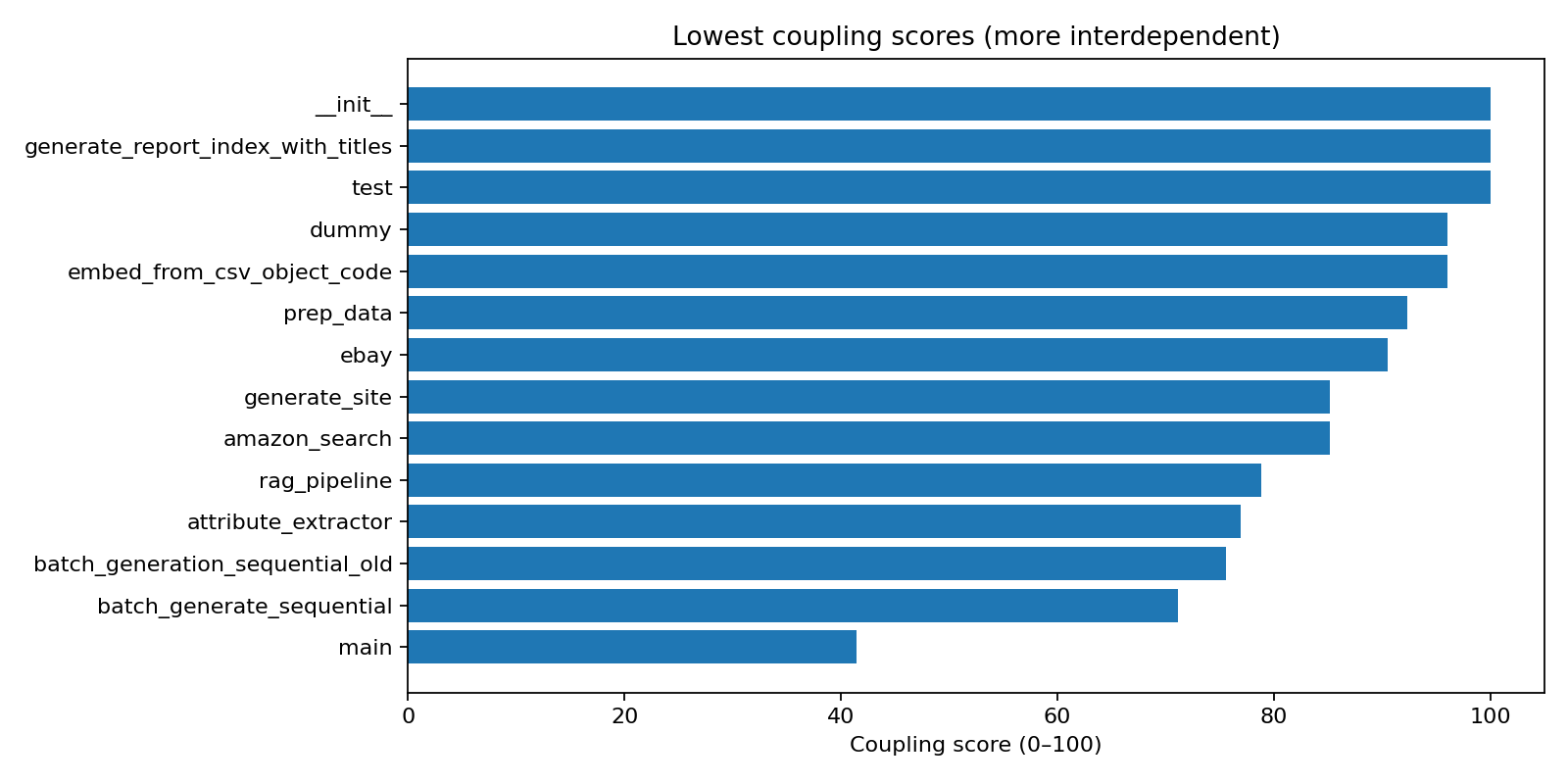
This chart highlights modules whose design suggests greater dependence on other internal modules. In a Python codebase, it is normal for an entrypoint/orchestrator module (often named main) to have higher coupling, because it wires together the application. The key question is whether that module is only orchestration, or whether it also contains substantial business logic (which would make it harder to change safely).
Chart 3 “Internal module import dependency matrix”
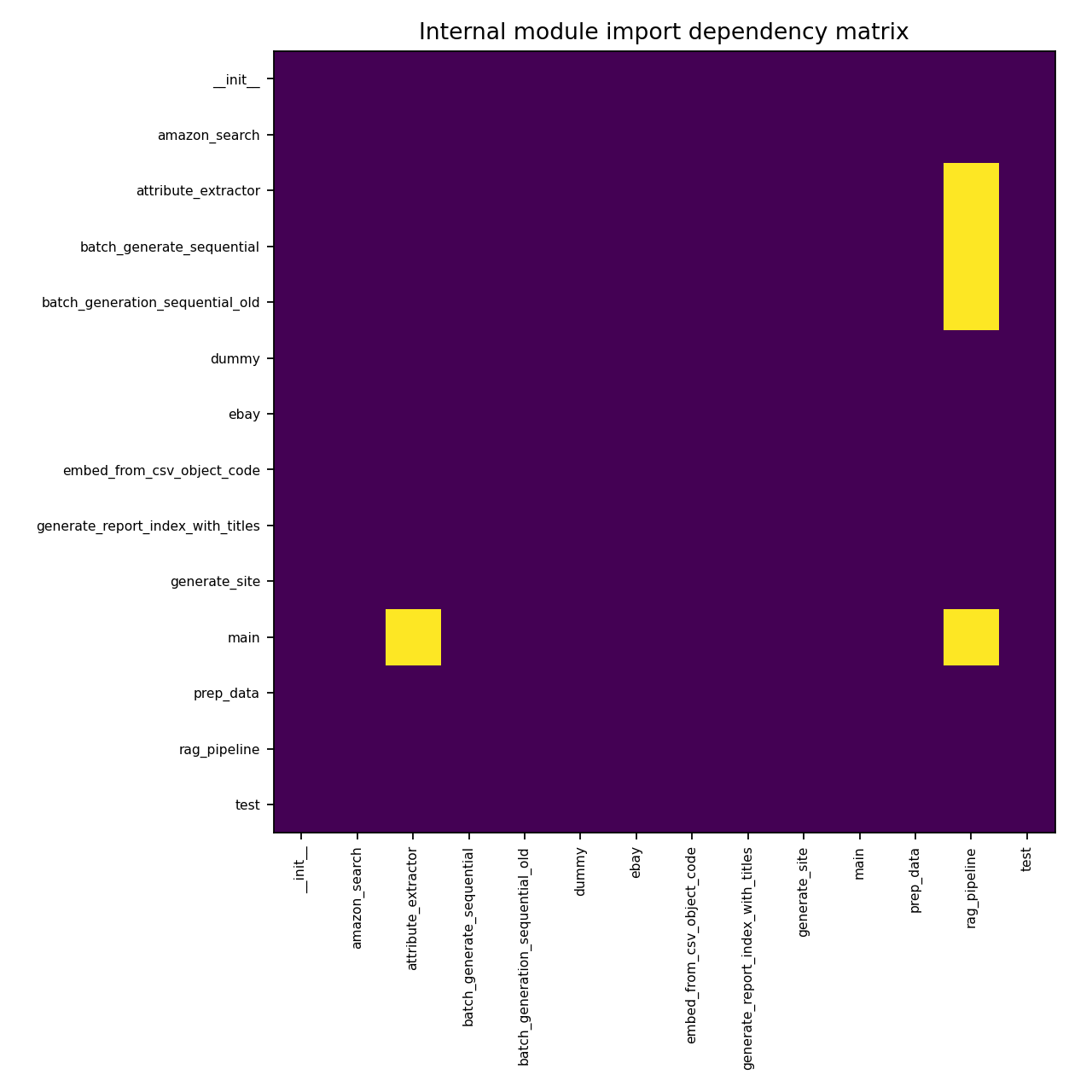
Bright cells indicate an internal import relationship. This matrix is useful for quickly spotting:
Hub modules that many others import (risk: ripple effects when changed)
Cycles (risk: brittle design and harder refactoring)
The matrix shows few internal edges and no obvious dense cyclic clusters, which supports the “generally loosely coupled” conclusion.
Findings and interpretation (what the results suggest)
Coupling is generally healthy; one module appears to be a hub
Overall internal coupling appears low: most modules import few (or no) internal modules, and the dependency matrix shows a small number of internal edges rather than a dense web of dependencies.
A notable structural pattern is a pipeline module that is imported by multiple others. This is not inherently bad—many systems have a core orchestration/pipeline module—but it becomes a risk if:
The module’s public surface area is large and unstable, or
Many modules reach into its internals rather than using a small, stable interface.
Practical assessment: Treat the pipeline module as a stable “core API”. If it must evolve frequently, consider extracting stable interfaces (facade functions/classes) so upstream modules depend on fewer details.
Cohesion issues concentrate in a handful of modules (function-cluster splits)
The lowest function-based cohesion modules appear consistent with these common Python patterns:
“Prep / utility” modules
These often become catch-alls (file I/O, transformation, validation, ad hoc scripts). The low cohesion signal is usually a sign that the module contains multiple unrelated tasks or two separate workflows living in one file.Extraction / integration modules
These modules often combine:parsing/normalization,
schema mapping,
external calls,
response shaping, and
error handling
When these concerns sit together, internal function-call structure frequently splits into clusters, which is what the “components > 1” signal is trying to reveal.
Pipeline modules
Pipeline modules commonly orchestrate multiple stages. Lower cohesion is expected if the module mixes:stage implementations (how each step works), and
orchestration (the ordering/wiring of steps), and
environment/config/client initialization
Splitting “pipeline wiring” from “pipeline stages” often improves cohesion while keeping the same behavior.
Practical assessment: In this codebase, the function-based cohesion view is identifying likely “mixed responsibility” modules more credibly than class-method cohesion would, because most classes are not behavior-heavy.
Detail Module Metrics Review
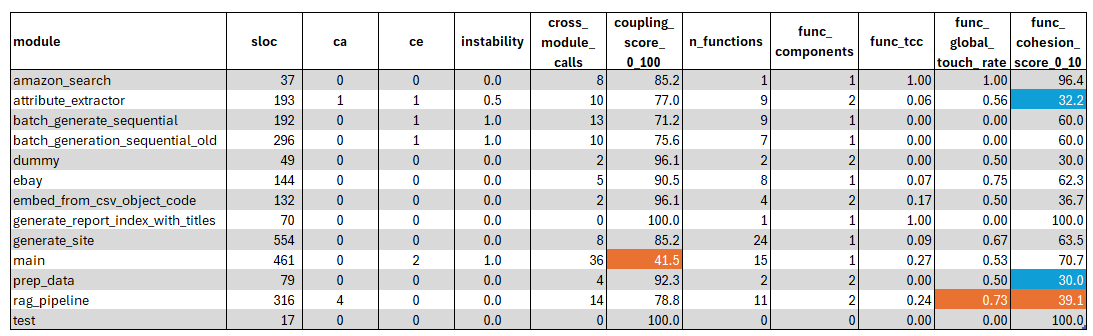
module
Measures: The internal module name (derived from the
.pyfilename/stem).Insights from the table: Two modules stand out as architectural “centers”:
rag_pipeline(highest Ca) andmain(lowest coupling score, highest cross-module calls), suggesting a hub-and-orchestrator shape.
sloc
Measures: Source Lines of Code (non-blank, non-comment lines). A rough proxy for size/complexity.
Insights: The largest modules are
generate_site(554 SLOC) andmain(461 SLOC)—good candidates to review first because size increases the chance of mixed responsibilities even when metrics look “okay.”
ca (afferent coupling)
Measures: Number of other internal modules that depend on (import) this module.
Insights:
rag_pipelinehas Ca = 4, meaning it has the broadest internal “blast radius.” Changes there are more likely to ripple outward than changes in most other modules.
ce (efferent coupling)
Measures: Number of internal modules this module depends on (imports).
Insights:
mainhas Ce = 2 (highest shown). Most other modules have Ce = 0 or 1, reinforcing that internal import coupling is generally low.
instability
Measures:
Ce / (Ca + Ce), ranging 0–1.Near 0: stable (many depend on it, but it depends on few).
Near 1: unstable (depends on others more than others depend on it).
Insights:
mainshows 1.00 (expected for an orchestrator/entrypoint).attribute_extractorat 0.50 indicates it’s both depended-on and dependent—often a sign it sits “in the middle” of a workflow.
cross_module_calls
Measures: Count of call sites to imported things (a proxy for cross-module interaction, not strictly internal-only).
Insights:
mainis highest (36)—consistent with orchestration/wiring.rag_pipeline(14) andbatch_generate_sequential(13) are also interaction-heavy, suggesting they integrate multiple functions/services.
coupling_score_0_100
Measures: A heuristic score where higher = less interdependent (loosely coupled). It penalizes higher
Ceandcross_module_calls.Insights:
mainis lowest (42) → it’s the most interdependent module by this heuristic.Many others are high (often 85–100) → the codebase appears loosely coupled at the internal import layer.
n_functions
Measures: Count of top-level functions detected in the module.
Insights:
generate_site(24),main(15),rag_pipeline(11), andattribute_extractor(9) carry most of the function-level behavior. These are the best targets for function-based cohesion review.
func_components
Measures: LCOM4-style component count over functions:
Functions are connected if they call each other internally or share module-global reads.
1 is best (one connected “family” of functions). >1 suggests multiple disconnected clusters (often multiple responsibilities).
Insights: The biggest red flags are modules with 2 components:
attribute_extractor(2),rag_pipeline(2),embed_from_csv_object_code(2),prep_data(2),dummy(2)These behave like “two mini-modules in one file,” which is a classic low-cohesion pattern.
func_tcc
Measures: TCC-like score for functions: fraction of function pairs that share at least one module-global read (0–1).
Insights:
Very low values (e.g.,
attribute_extractor0.06,ebay0.07,generate_site0.09) mean functions rarely share globals—often indicating either:functions are independent utilities (fine), or
the module contains unrelated function groups (matches the
func_componentssignal).
main0.27 andrag_pipeline0.24 suggest some shared context, but not strongly “single-purpose” via shared state.
func_global_touch_rate
Measures: Proportion of functions that touch module-global state (read or write), 0–1.
Insights:
Higher values can indicate hidden coupling inside the module (shared state as an implicit interface).
rag_pipelineis highest (0.73) → many functions rely on module-level state; this can reduce testability and make changes riskier.amazon_searchshows 1.00 but has only 1 function—this is a good example where the metric is less informative because the module is too small to interpret structurally.
func_cohesion_score_0_100
Measures: A heuristic rollup for function-based cohesion (higher = more cohesive) combining
func_components,func_tcc, and a penalty for very highfunc_global_touch_rate.Insights (most important “what to fix first” list):
Lowest cohesion:
attribute_extractor(32),prep_data(30),dummy(30),rag_pipeline(39),embed_from_csv_object_code(37).Common pattern:
func_components = 2plus moderate/high global-touch → likely mixed responsibilities.
Mid-range cohesion:
batch_generate_sequential(60) /batch_generation_sequential_old(60) /ebay(62) /generate_site(64).High cohesion scores (often 1-function modules):
generate_report_index_with_titles(100),test(100),amazon_search(96).Interpret these cautiously: a single function can’t fragment much, so scores tend to be high by construction.
Recommended remediation plan (actionable next steps)
Step 1: Triage by “fix value”
Focus first on modules that are:
Low cohesion and highly depended upon (hub risk), or
Low cohesion and central to frequent change (iteration velocity risk)
This typically means prioritizing: hub and the lowest-cohesion “prep/extractor” modules.
Step 2: Refactor low-cohesion modules using “split by responsibility”
For each low-cohesion module, identify distinct responsibility clusters and split into submodules, for example:
attribute-extractor.py→extractor_core.py(pure extraction logic)schemas.py(request/response models, validation)integrations.py(external calls)attribute_extractor.py(thin facade / public API)
prep-data.py→io_loaders.py(file/IO)transforms.py(pure transformations)prep_data.py(thin CLI wrapper, if needed)
Step 3: Stabilize hub module dependencies
If rag-pipeline is imported broadly:
Reduce its public surface area to a small set of stable functions/classes (facade), and
Push volatile details behind those stable entrypoints so callers do not import internals.
Step 4: Re-run and track deltas as KPIs

After each refactor iteration, re-run the tool and track:
Median function cohesion score
Count of modules with multiple function components
Hub module Ca/Ce and cross-module call counts
“Worst N” modules trend lines (are the same modules repeatedly appearing?)
This turns the analysis into an operational KPI loop rather than a one-time report.
Limitations (how much confidence to place in the metrics)
This is conservative static analysis; dynamic imports, reflection, and runtime dispatch can hide or distort dependencies.
Function cohesion here is a heuristic; it’s most useful for relative comparisons (“which modules are worst?”) and trend tracking (“did this refactor improve cohesion?”), not for claiming a precise absolute quality score.
Modules with very few functions can appear “high cohesion” by construction; interpret those as “insufficient evidence” rather than “excellent design.”
Appendix B — Python Analyzer Code
"""
cc_metrics.py
Static cohesion + coupling analysis for Python codebases (AST-based).
Outputs (always):
- class_metrics.csv
- module_metrics.csv
- function_metrics.csv
- cc_report.json
- summary.txt
Outputs (if matplotlib is installed):
- charts/worst_classes_cohesion.png
- charts/worst_modules_coupling.png
- charts/dependency_matrix.png
- charts/worst_modules_function_cohesion.png
- charts/module_deps.dot
Notes:
- This is conservative static analysis. Dynamic dispatch/reflection can reduce accuracy.
- Class cohesion uses self.<attr> usage as the instance-variable proxy (LCOM/TCC family ideas).
- Function/module cohesion is designed for Python codebases where behavior is often in module-level functions.
"""
from __future__ import annotations
import ast
import json
import math
import os
from dataclasses import dataclass, asdict, field
from pathlib import Path
from typing import Any, Dict, Iterable, List, Optional, Set, Tuple
# -----------------------------
# Data models
# -----------------------------
@dataclass
class MethodInfo:
qualname: str
name: str
lineno: int
attrs_used: Set[str] = field(default_factory=set)
self_calls: Set[str] = field(default_factory=set) # method names called on self
external_calls: Set[str] = field(default_factory=set) # module_alias.func or from-import func
@dataclass
class ClassMetrics:
file: str
class_name: str
lineno: int
n_methods: int
lcom_ck: float
lcom4_components: int
tcc: float
cohesion_score_0_100: float
methods: List[MethodInfo] = field(default_factory=list)
@dataclass
class FunctionInfo:
file: str
module: str
func_name: str
lineno: int
internal_calls: Set[str] = field(default_factory=set) # calls to other top-level functions in same module
globals_read: Set[str] = field(default_factory=set) # module-level vars read
globals_written: Set[str] = field(default_factory=set) # module-level vars written via 'global' statement
external_calls: Set[str] = field(default_factory=set) # module_alias.func or from-import func
@dataclass
class FunctionMetrics:
file: str
module: str
func_name: str
lineno: int
internal_calls_count: int
globals_read_count: int
globals_written_count: int
external_calls_count: int
@dataclass
class ModuleMetrics:
file: str
module: str
sloc: int
imports: Set[str] = field(default_factory=set) # all imports (as written)
internal_deps: Set[str] = field(default_factory=set) # imports that match analyzed modules (top-level heuristic)
ca: int = 0 # afferent coupling
ce: int = 0 # efferent coupling
instability: float = 0.0
cross_module_calls: int = 0
coupling_score_0_100: float = 0.0
# Function/module cohesion (Python-friendly)
n_functions: int = 0
func_components: int = 0
func_tcc: float = 0.0
func_global_touch_rate: float = 0.0
func_cohesion_score_0_100: float = 0.0
@dataclass
class ProjectReport:
root: str
analyzed_files: List[str]
class_metrics: List[ClassMetrics]
module_metrics: List[ModuleMetrics]
function_details: List[FunctionInfo]
function_metrics: List[FunctionMetrics]
kpis: Dict[str, Any]
# -----------------------------
# AST helpers
# -----------------------------
class _ImportTracker(ast.NodeVisitor):
"""Collect imports and build alias maps so calls can be attributed approximately."""
def __init__(self) -> None:
self.imports: Set[str] = set()
self.alias_to_module: Dict[str, str] = {} # import x as y -> y : x
self.func_to_module: Dict[str, str] = {} # from x import f as g -> g : x
def visit_Import(self, node: ast.Import) -> None:
for a in node.names:
mod = a.name
self.imports.add(mod)
asname = a.asname or mod.split(".")[0]
self.alias_to_module[asname] = mod
self.generic_visit(node)
def visit_ImportFrom(self, node: ast.ImportFrom) -> None:
if node.module is None:
return
mod = node.module
self.imports.add(mod)
for a in node.names:
if a.name == "*":
continue
asname = a.asname or a.name
self.func_to_module[asname] = mod
self.generic_visit(node)
class _ClassAnalyzer(ast.NodeVisitor):
"""For each class, collect per-method self-attribute usage and self-method calls."""
def __init__(self, file: str, module_alias_to_mod: Dict[str, str], func_to_mod: Dict[str, str]) -> None:
self.file = file
self.module_alias_to_mod = module_alias_to_mod
self.func_to_mod = func_to_mod
self.classes: List[ClassMetrics] = []
self._current_class: Optional[str] = None
self._current_class_lineno: int = 0
def visit_ClassDef(self, node: ast.ClassDef) -> None:
prev_class = self._current_class
prev_lineno = self._current_class_lineno
self._current_class = node.name
self._current_class_lineno = getattr(node, "lineno", 0)
methods: List[MethodInfo] = []
for item in node.body:
if isinstance(item, (ast.FunctionDef, ast.AsyncFunctionDef)):
methods.append(self._analyze_method(item))
self.classes.append(_compute_class_metrics(
file=self.file,
class_name=self._current_class,
lineno=self._current_class_lineno,
methods=methods,
))
self.generic_visit(node)
self._current_class = prev_class
self._current_class_lineno = prev_lineno
def _analyze_method(self, node: ast.AST) -> MethodInfo:
name = getattr(node, "name", "<lambda>")
lineno = getattr(node, "lineno", 0)
qualname = f"{self._current_class}.{name}" if self._current_class else name
mi = MethodInfo(qualname=qualname, name=name, lineno=lineno)
tracker = self
class _MethodVisitor(ast.NodeVisitor):
def visit_Attribute(self, n: ast.Attribute) -> None:
if isinstance(n.value, ast.Name) and n.value.id == "self":
mi.attrs_used.add(n.attr)
self.generic_visit(n)
def visit_Call(self, n: ast.Call) -> None:
# self.method(...)
if isinstance(n.func, ast.Attribute) and isinstance(n.func.value, ast.Name):
if n.func.value.id == "self":
mi.self_calls.add(n.func.attr)
else:
alias = n.func.value.id
if alias in tracker.module_alias_to_mod:
mi.external_calls.add(f"{alias}.{n.func.attr}")
# func imported via `from x import func as f`
if isinstance(n.func, ast.Name) and n.func.id in tracker.func_to_mod:
mi.external_calls.add(n.func.id)
self.generic_visit(n)
_MethodVisitor().visit(node)
return mi
class _ModuleFunctionAnalyzer:
"""
Analyze top-level (module) functions:
- internal calls (to other top-level functions in same file)
- shared module variables (module-level assignments read inside functions)
- external calls through imported module aliases / from-import names
"""
def __init__(self, file: str, module_name: str, module_alias_to_mod: Dict[str, str], func_to_mod: Dict[str, str]) -> None:
self.file = file
self.module_name = module_name
self.module_alias_to_mod = module_alias_to_mod
self.func_to_mod = func_to_mod
self.module_vars: Set[str] = set()
self.function_defs: Dict[str, ast.AST] = {}
def analyze(self, tree: ast.AST) -> List[FunctionInfo]:
if not isinstance(tree, ast.Module):
return []
# 1) Collect module-level variables (assigned at top-level)
for node in tree.body:
if isinstance(node, ast.Assign):
for t in node.targets:
for name in self._extract_target_names(t):
if not name.startswith("_"):
self.module_vars.add(name)
elif isinstance(node, ast.AnnAssign):
for name in self._extract_target_names(node.target):
if not name.startswith("_"):
self.module_vars.add(name)
elif isinstance(node, ast.AugAssign):
for name in self._extract_target_names(node.target):
if not name.startswith("_"):
self.module_vars.add(name)
# 2) Collect top-level function defs
for node in tree.body:
if isinstance(node, (ast.FunctionDef, ast.AsyncFunctionDef)):
self.function_defs[node.name] = node
fn_names = set(self.function_defs.keys())
infos: List[FunctionInfo] = []
# 3) Analyze each function body
for fn_name, fn_node in self.function_defs.items():
fi = FunctionInfo(
file=self.file,
module=self.module_name,
func_name=fn_name,
lineno=getattr(fn_node, "lineno", 0),
)
declared_globals: Set[str] = set()
outer = self
class _FV(ast.NodeVisitor):
def visit_Global(self, n: ast.Global) -> None:
for nm in n.names:
declared_globals.add(nm)
self.generic_visit(n)
def visit_Call(self, n: ast.Call) -> None:
# internal call: foo(...)
if isinstance(n.func, ast.Name) and n.func.id in fn_names:
fi.internal_calls.add(n.func.id)
# external call: alias.func(...)
if isinstance(n.func, ast.Attribute) and isinstance(n.func.value, ast.Name):
alias = n.func.value.id
if alias in outer.module_alias_to_mod:
fi.external_calls.add(f"{alias}.{n.func.attr}")
# external call: func imported via `from x import func as f`
if isinstance(n.func, ast.Name) and n.func.id in outer.func_to_mod:
fi.external_calls.add(n.func.id)
self.generic_visit(n)
def visit_Name(self, n: ast.Name) -> None:
# reading a module variable
if isinstance(n.ctx, ast.Load) and n.id in outer.module_vars:
fi.globals_read.add(n.id)
# writing a module variable requires 'global' declaration
if isinstance(n.ctx, ast.Store) and n.id in declared_globals and n.id in outer.module_vars:
fi.globals_written.add(n.id)
self.generic_visit(n)
_FV().visit(fn_node)
infos.append(fi)
return infos
@staticmethod
def _extract_target_names(target: ast.AST) -> Set[str]:
names: Set[str] = set()
if isinstance(target, ast.Name):
names.add(target.id)
elif isinstance(target, (ast.Tuple, ast.List)):
for elt in target.elts:
names |= _ModuleFunctionAnalyzer._extract_target_names(elt)
# Skip Attribute/Subscript targets at module scope
return names
# -----------------------------
# Metrics core
# -----------------------------
def _pairs(items: List[str]) -> Iterable[Tuple[str, str]]:
for i in range(len(items)):
for j in range(i + 1, len(items)):
yield items[i], items[j]
def _compute_lcom_ck(method_attrs: Dict[str, Set[str]]) -> float:
"""
CK-style LCOM:
P = method pairs with no shared instance variables
Q = method pairs with shared instance variables
LCOM = |P| - |Q| if positive else 0
"""
methods = list(method_attrs.keys())
if len(methods) < 2:
return 0.0
p = 0
q = 0
for m1, m2 in _pairs(methods):
if method_attrs[m1].intersection(method_attrs[m2]):
q += 1
else:
p += 1
return float(max(p - q, 0))
def _connected_components(nodes: List[str], edges: Set[Tuple[str, str]]) -> int:
if not nodes:
return 0
adj: Dict[str, Set[str]] = {n: set() for n in nodes}
for a, b in edges:
adj[a].add(b)
adj[b].add(a)
seen: Set[str] = set()
comps = 0
for n in nodes:
if n in seen:
continue
comps += 1
stack = [n]
while stack:
cur = stack.pop()
if cur in seen:
continue
seen.add(cur)
stack.extend(list(adj[cur] - seen))
return comps
def _compute_lcom4(method_attrs: Dict[str, Set[str]], method_calls: Dict[str, Set[str]]) -> int:
"""
LCOM4-style components:
number of connected components in method graph where an edge exists if:
- methods share a self-attribute, OR
- one calls the other via self.<method>()
"""
methods = list(method_attrs.keys())
if len(methods) <= 1:
return 1 if methods else 0
edges: Set[Tuple[str, str]] = set()
for m1, m2 in _pairs(methods):
if method_attrs[m1].intersection(method_attrs[m2]):
edges.add((m1, m2))
for m, callees in method_calls.items():
for c in callees:
if c in method_attrs:
edges.add((m, c))
return _connected_components(methods, edges)
def _compute_tcc(method_attrs: Dict[str, Set[str]]) -> float:
"""TCC: directly-connected method pairs / all possible pairs (direct = share a self-attribute)."""
methods = list(method_attrs.keys())
n = len(methods)
if n < 2:
return 1.0
possible = n * (n - 1) / 2
connected = 0
for m1, m2 in _pairs(methods):
if method_attrs[m1].intersection(method_attrs[m2]):
connected += 1
return float(connected / possible) if possible else 1.0
def _cohesion_score(lcom4_components: int, tcc: float) -> float:
"""
Dashboard-friendly heuristic (0–100). Not a research standard metric.
- LCOM4=1 best; higher components reduce score
- TCC increases score linearly
"""
if lcom4_components <= 0:
return 0.0
lcom_term = 1.0 / lcom4_components
score = 100.0 * (0.65 * lcom_term + 0.35 * max(0.0, min(1.0, tcc)))
return float(max(0.0, min(100.0, score)))
def _coupling_score(ce: int, cross_calls: int, ca: int) -> float:
"""
Dashboard-friendly heuristic (0–100). Not a research standard metric.
Penalizes efferent coupling and cross-module call edges; lightly rewards Ca.
"""
penalty = ce + 0.25 * cross_calls
base = 100.0 * math.exp(-0.08 * penalty)
bonus = min(10.0, 2.0 * math.log1p(ca))
return float(max(0.0, min(100.0, base + bonus)))
def _compute_class_metrics(file: str, class_name: str, lineno: int, methods: List[MethodInfo]) -> ClassMetrics:
method_attrs = {m.name: set(m.attrs_used) for m in methods}
method_calls = {m.name: set(m.self_calls) for m in methods}
lcom_ck = _compute_lcom_ck(method_attrs)
lcom4 = _compute_lcom4(method_attrs, method_calls)
tcc = _compute_tcc(method_attrs)
score = _cohesion_score(lcom4, tcc)
return ClassMetrics(
file=file,
class_name=class_name,
lineno=lineno,
n_methods=len(methods),
lcom_ck=lcom_ck,
lcom4_components=lcom4,
tcc=tcc,
cohesion_score_0_100=score,
methods=methods,
)
def _count_sloc(text: str) -> int:
sloc = 0
for ln in text.splitlines():
s = ln.strip()
if not s or s.startswith("#"):
continue
sloc += 1
return sloc
# -----------------------------
# Function/module cohesion helpers
# -----------------------------
def _compute_function_tcc(function_globals: Dict[str, Set[str]]) -> float:
"""
TCC-like for functions: fraction of function pairs that share >=1 module-global read.
"""
funcs = list(function_globals.keys())
n = len(funcs)
if n < 2:
return 1.0 if n == 1 else 0.0
possible = n * (n - 1) / 2
connected = 0
for f1, f2 in _pairs(funcs):
if function_globals[f1].intersection(function_globals[f2]):
connected += 1
return float(connected / possible) if possible else 1.0
def _compute_function_components(function_globals: Dict[str, Set[str]], call_edges: Dict[str, Set[str]]) -> int:
"""
LCOM4-style components for functions:
Edge exists if:
- function calls another function in same module, OR
- they share >=1 module-global variable read
"""
funcs = list(function_globals.keys())
if len(funcs) <= 1:
return 1 if funcs else 0
edges: Set[Tuple[str, str]] = set()
# shared-global edges
for f1, f2 in _pairs(funcs):
if function_globals[f1].intersection(function_globals[f2]):
edges.add((f1, f2))
# call edges (undirected for component counting)
for f, callees in call_edges.items():
for c in callees:
if c in function_globals:
edges.add((f, c))
return _connected_components(funcs, edges)
def _function_cohesion_score(components: int, tcc: float, global_touch_rate: float) -> float:
"""
Heuristic 0–100 module function cohesion score:
- components: 1 is best; more components reduces score
- tcc: higher is better
- global_touch_rate: very high can indicate heavy shared-state reliance; apply mild penalty
"""
if components <= 0:
return 0.0
comp_term = 1.0 / components
score = 100.0 * (0.60 * comp_term + 0.40 * max(0.0, min(1.0, tcc)))
# Mild penalty if most functions touch globals (tune/remove if you prefer)
penalty = 12.0 * max(0.0, global_touch_rate - 0.70)
score -= penalty
return float(max(0.0, min(100.0, score)))
# -----------------------------
# File selection utilities
# ----------------------------
def _expand_paths(paths: List[str], ignore_dirs: Set[str]) -> List[Path]:
out: List[Path] = []
for p in paths:
pth = Path(p)
if any(ch in p for ch in ["*", "?", "["]): # glob
for g in sorted(Path().glob(p)):
out.extend(_expand_paths([str(g)], ignore_dirs))
continue
if pth.is_dir():
for root, dirs, files in os.walk(pth):
dirs[:] = [d for d in dirs if d not in ignore_dirs]
for fn in files:
if fn.endswith(".py"):
out.append(Path(root) / fn)
continue
if pth.is_file() and pth.suffix == ".py":
out.append(pth)
# de-dup
seen = set()
uniq: List[Path] = []
for f in out:
s = str(f.resolve())
if s not in seen:
seen.add(s)
uniq.append(f)
return uniq
def _common_parent(files: List[Path]) -> Path:
parents = [f.resolve().parent for f in files]
return Path(os.path.commonpath([str(p) for p in parents]))
def _path_to_module(file: Path, root: Path) -> str:
# Use file stem; this matches simple script-style repos well.
return file.stem
# -----------------------------
# KPIs + output formatting
# -----------------------------
def _median(xs: List[float]) -> float:
if not xs:
return 0.0
xs = sorted(xs)
n = len(xs)
mid = n // 2
return float(xs[mid]) if n % 2 else float((xs[mid - 1] + xs[mid]) / 2)
def _percentile(xs: List[int], p: int) -> int:
if not xs:
return 0
xs = sorted(xs)
idx = int(math.ceil((p / 100) * len(xs))) - 1
idx = max(0, min(len(xs) - 1, idx))
return int(xs[idx])
def _compute_kpis(classes: List[ClassMetrics], modules: List[ModuleMetrics]) -> Dict[str, Any]:
k: Dict[str, Any] = {}
# Class cohesion KPIs (only for classes with >=1 method)
classes_with_methods = [c for c in classes if c.n_methods > 0]
k["classes_count"] = len(classes)
k["classes_with_methods_count"] = len(classes_with_methods)
if classes_with_methods:
lcom4 = [c.lcom4_components for c in classes_with_methods]
tcc = [c.tcc for c in classes_with_methods]
score = [c.cohesion_score_0_100 for c in classes_with_methods]
k["pct_classes_lcom4_eq_1"] = round(100.0 * sum(1 for v in lcom4 if v == 1) / len(lcom4), 2)
k["median_tcc"] = round(_median(tcc), 3)
k["median_class_cohesion_score"] = round(_median(score), 1)
else:
k["pct_classes_lcom4_eq_1"] = 0.0
k["median_tcc"] = 0.0
k["median_class_cohesion_score"] = 0.0
# Coupling KPIs
k["modules_count"] = len(modules)
if modules:
ce = [m.ce for m in modules]
inst = [m.instability for m in modules]
cscore = [m.coupling_score_0_100 for m in modules]
k["p90_ce"] = _percentile(ce, 90)
k["median_instability"] = round(_median(inst), 3)
k["median_coupling_score"] = round(_median(cscore), 1)
else:
k["p90_ce"] = 0
k["median_instability"] = 0.0
k["median_coupling_score"] = 0.0
# Function/module cohesion KPIs
modules_with_funcs = [m for m in modules if m.n_functions > 0]
k["modules_with_functions_count"] = len(modules_with_funcs)
if modules_with_funcs:
fscore = [m.func_cohesion_score_0_100 for m in modules_with_funcs]
comps = [m.func_components for m in modules_with_funcs]
ftcc = [m.func_tcc for m in modules_with_funcs]
k["pct_modules_func_components_eq_1"] = round(100.0 * sum(1 for v in comps if v == 1) / len(comps), 2)
k["median_func_tcc"] = round(_median(ftcc), 3)
k["median_module_func_cohesion_score"] = round(_median(fscore), 1)
else:
k["pct_modules_func_components_eq_1"] = 0.0
k["median_func_tcc"] = 0.0
k["median_module_func_cohesion_score"] = 0.0
return k
def _csv(s: str) -> str:
s = s.replace('"', '""')
if any(c in s for c in [",", "\n", '"']):
return '"' + s + '"'
return s
def _class_csv(rows: List[ClassMetrics]) -> str:
cols = ["file", "class_name", "lineno", "n_methods", "lcom_ck", "lcom4_components", "tcc", "cohesion_score_0_100"]
lines = [",".join(cols)]
for r in rows:
lines.append(",".join([
_csv(r.file), _csv(r.class_name), str(r.lineno), str(r.n_methods),
f"{r.lcom_ck:.2f}", str(r.lcom4_components), f"{r.tcc:.3f}", f"{r.cohesion_score_0_100:.1f}",
]))
return "\n".join(lines) + "\n"
def _function_csv(rows: List[FunctionMetrics]) -> str:
cols = ["file","module","func_name","lineno","internal_calls_count","globals_read_count","globals_written_count","external_calls_count"]
lines = [",".join(cols)]
for r in rows:
lines.append(",".join([
_csv(r.file), _csv(r.module), _csv(r.func_name), str(r.lineno),
str(r.internal_calls_count), str(r.globals_read_count), str(r.globals_written_count), str(r.external_calls_count),
]))
return "\n".join(lines) + "\n"
def _module_csv(rows: List[ModuleMetrics]) -> str:
cols = [
"file","module","sloc",
"ca","ce","instability","cross_module_calls","coupling_score_0_100",
"n_functions","func_components","func_tcc","func_global_touch_rate","func_cohesion_score_0_100",
"internal_deps","imports"
]
lines = [",".join(cols)]
for r in rows:
lines.append(",".join([
_csv(r.file), _csv(r.module), str(r.sloc),
str(r.ca), str(r.ce), f"{r.instability:.3f}", str(r.cross_module_calls), f"{r.coupling_score_0_100:.1f}",
str(r.n_functions), str(r.func_components), f"{r.func_tcc:.3f}", f"{r.func_global_touch_rate:.3f}", f"{r.func_cohesion_score_0_100:.1f}",
_csv(" ".join(sorted(r.internal_deps))),
_csv(" ".join(sorted(r.imports))),
]))
return "\n".join(lines) + "\n"
def _summary_text(report: ProjectReport) -> str:
lines = []
lines.append("Cohesion + Coupling Report (static AST analysis)")
lines.append(f"Root: {report.root}")
lines.append(f"Files analyzed: {len(report.analyzed_files)}")
lines.append("")
lines.append("KPIs:")
for k, v in report.kpis.items():
lines.append(f"- {k}: {v}")
lines.append("")
return "\n".join(lines)
# -----------------------------
# Charts + GraphViz export
# -----------------------------
def _write_charts(report: ProjectReport, out: Path) -> None:
import matplotlib.pyplot as plt
charts = out / "charts"
charts.mkdir(exist_ok=True)
# Worst classes by cohesion (ignore classes with 0 methods)
classes = [c for c in report.class_metrics if c.n_methods > 0]
worst_classes = sorted(classes, key=lambda c: c.cohesion_score_0_100)[:15]
if worst_classes:
labels = [c.class_name for c in worst_classes]
values = [c.cohesion_score_0_100 for c in worst_classes]
plt.figure(figsize=(10, 5))
plt.barh(labels, values)
plt.xlabel("Class cohesion score (0–100)")
plt.title("Lowest class cohesion (heuristic)")
plt.tight_layout()
plt.savefig(charts / "worst_classes_cohesion.png", dpi=160)
plt.close()
# Modules with lowest coupling scores
worst_modules = sorted(report.module_metrics, key=lambda m: m.coupling_score_0_100)[:15]
if worst_modules:
labels = [m.module for m in worst_modules]
values = [m.coupling_score_0_100 for m in worst_modules]
plt.figure(figsize=(10, 5))
plt.barh(labels, values)
plt.xlabel("Coupling score (0–100)")
plt.title("Lowest coupling scores (more interdependent)")
plt.tight_layout()
plt.savefig(charts / "worst_modules_coupling.png", dpi=160)
plt.close()
# Worst modules by function cohesion (lowest score)
mods = [m for m in report.module_metrics if m.n_functions > 0]
worst_func = sorted(mods, key=lambda m: m.func_cohesion_score_0_100)[:15]
if worst_func:
labels = [m.module for m in worst_func]
values = [m.func_cohesion_score_0_100 for m in worst_func]
plt.figure(figsize=(10, 5))
plt.barh(labels, values)
plt.xlabel("Function-based module cohesion score (0–100)")
plt.title("Lowest function-based module cohesion (heuristic)")
plt.tight_layout()
plt.savefig(charts / "worst_modules_function_cohesion.png", dpi=160)
plt.close()
# Internal import dependency matrix
mods_names = sorted({m.module for m in report.module_metrics})
idx = {m: i for i, m in enumerate(mods_names)}
n = len(mods_names)
if n >= 2:
mat = [[0 for _ in range(n)] for _ in range(n)]
for mm in report.module_metrics:
i = idx[mm.module]
for dep in mm.internal_deps:
j = idx.get(dep)
if j is not None:
mat[i][j] = 1
plt.figure(figsize=(8, 8))
plt.imshow(mat)
plt.xticks(range(n), mods_names, rotation=90, fontsize=7)
plt.yticks(range(n), mods_names, fontsize=7)
plt.title("Internal module import dependency matrix")
plt.tight_layout()
plt.savefig(charts / "dependency_matrix.png", dpi=160)
plt.close()
# GraphViz DOT for module deps
(charts / "module_deps.dot").write_text(_to_dot(report), encoding="utf-8")
def _to_dot(report: ProjectReport) -> str:
lines = ["digraph module_deps {", " rankdir=LR;"]
for m in report.module_metrics:
lines.append(f' "{m.module}";')
for m in report.module_metrics:
for dep in m.internal_deps:
lines.append(f' "{m.module}" -> "{dep}";')
lines.append("}")
return "\n".join(lines) + "\n"
# -----------------------------
# Public API
# -----------------------------
def analyze_paths(paths: List[str], root: Optional[str] = None, ignore_dirs: Optional[Set[str]] = None) -> ProjectReport:
ignore_dirs = ignore_dirs or {
".git", "__pycache__", ".mypy_cache", ".pytest_cache", ".tox",
".venv", "venv", "env", "site-packages", "dist", "build"
}
files = _expand_paths(paths, ignore_dirs)
if not files:
raise FileNotFoundError("No .py files found for the provided paths.")
root_path = Path(root) if root else _common_parent(files)
module_map = {str(f): _path_to_module(f, root_path) for f in files}
all_modules = set(module_map.values())
class_metrics: List[ClassMetrics] = []
module_imports: Dict[str, Set[str]] = {}
module_cross_calls: Dict[str, int] = {}
module_sloc: Dict[str, int] = {}
function_details: List[FunctionInfo] = []
function_metrics_rows: List[FunctionMetrics] = []
# Pass 1: parse files
for f in files:
src = f.read_text(encoding="utf-8", errors="ignore")
module_sloc[str(f)] = _count_sloc(src)
try:
tree = ast.parse(src, filename=str(f))
except SyntaxError:
module_imports[str(f)] = set()
module_cross_calls[str(f)] = 0
continue
# Imports (needed for external call attribution)
imp = _ImportTracker()
imp.visit(tree)
module_imports[str(f)] = set(imp.imports)
# Class analysis
ca = _ClassAnalyzer(str(f), imp.alias_to_module, imp.func_to_module)
ca.visit(tree)
class_metrics.extend(ca.classes)
# Function analysis (top-level functions)
module_name = module_map.get(str(f), f.stem)
mfa = _ModuleFunctionAnalyzer(
file=str(f),
module_name=module_name,
module_alias_to_mod=imp.alias_to_module,
func_to_mod=imp.func_to_module,
)
f_infos = mfa.analyze(tree)
function_details.extend(f_infos)
# Cross-module call edges (approx): class external calls + function external calls
cross_calls = 0
for cm in ca.classes:
for mi in cm.methods:
cross_calls += len(mi.external_calls)
for fi in f_infos:
cross_calls += len(fi.external_calls)
module_cross_calls[str(f)] = cross_calls
# Index function info by file
funcs_by_file: Dict[str, List[FunctionInfo]] = {}
for fi in function_details:
funcs_by_file.setdefault(fi.file, []).append(fi)
# Determine internal deps (imports that match analyzed top-level modules)
file_to_internal_deps: Dict[str, Set[str]] = {}
for fstr, imports in module_imports.items():
internal = set()
for imp_mod in imports:
top = imp_mod.split(".")[0]
if top in all_modules:
internal.add(top)
file_to_internal_deps[fstr] = internal
# Build Ca/Ce from internal deps (module name based)
incoming: Dict[str, Set[str]] = {m: set() for m in all_modules}
outgoing: Dict[str, Set[str]] = {m: set() for m in all_modules}\
for fstr, mod in module_map.items():
deps = file_to_internal_deps.get(fstr, set())
outgoing[mod] = set(deps)
for d in deps:
incoming[d].add(mod)
module_metrics: List[ModuleMetrics] = []
# Build per-file function metrics rows and per-module function cohesion
for fstr, mod in module_map.items():
# Coupling
ce = len(outgoing.get(mod, set()))
ca_count = len(incoming.get(mod, set()))
instab = float(ce / (ca_count + ce)) if (ca_count + ce) > 0 else 0.0
cross_calls = int(module_cross_calls.get(fstr, 0))
cscore = _coupling_score(ce=ce, cross_calls=cross_calls, ca=ca_count)
# Function cohesion for this module/file
fis = funcs_by_file.get(fstr, [])
n_funcs = len(fis)
if n_funcs == 0:
func_components = 0
func_tcc = 0.0
global_touch_rate = 0.0
func_score = 100.0 # no functions: not a cohesion concern by this view
else:
function_globals = {fi.func_name: set(fi.globals_read) for fi in fis}
call_edges = {fi.func_name: set(fi.internal_calls) for fi in fis}
func_components = _compute_function_components(function_globals, call_edges)
func_tcc = _compute_function_tcc(function_globals)
touched = sum(1 for fi in fis if (fi.globals_read or fi.globals_written))
global_touch_rate = float(touched / n_funcs) if n_funcs else 0.0
func_score = _function_cohesion_score(func_components, func_tcc, global_touch_rate)
# Per-function metrics rows
for fi in fis:
function_metrics_rows.append(FunctionMetrics(
file=fi.file,
module=fi.module,
func_name=fi.func_name,
lineno=fi.lineno,
internal_calls_count=len(fi.internal_calls),
globals_read_count=len(fi.globals_read),
globals_written_count=len(fi.globals_written),
external_calls_count=len(fi.external_calls),
))
module_metrics.append(ModuleMetrics(
file=fstr,
module=mod,
sloc=int(module_sloc.get(fstr, 0)),
imports=set(module_imports.get(fstr, set())),
internal_deps=set(outgoing.get(mod, set())),
ca=ca_count,
ce=ce,
instability=instab,
cross_module_calls=cross_calls,
coupling_score_0_100=cscore,
n_functions=n_funcs,
func_components=func_components,
func_tcc=func_tcc,
func_global_touch_rate=global_touch_rate,
func_cohesion_score_0_100=func_score,
))
kpis = _compute_kpis(class_metrics, module_metrics)
return ProjectReport(
root=str(root_path),
analyzed_files=[str(f) for f in files],
class_metrics=class_metrics,
module_metrics=module_metrics,
function_details=function_details,
function_metrics=function_metrics_rows,
kpis=kpis,
)
def _json_fallback(o: Any) -> Any:
if isinstance(o, set):
return sorted(list(o))
return str(o)
def save_report(report: ProjectReport, outdir: str) -> Dict[str, str]:
out = Path(outdir)
out.mkdir(parents=True, exist_ok=True)
produced: Dict[str, str] = {}
# JSON
json_path = out / "cc_report.json"
json_path.write_text(json.dumps(asdict(report), indent=2, default=_json_fallback), encoding="utf-8")
produced["json"] = str(json_path)
# CSVs
class_csv = out / "class_metrics.csv"
class_csv.write_text(_class_csv(report.class_metrics), encoding="utf-8")
produced["class_csv"] = str(class_csv)
module_csv = out / "module_metrics.csv"
module_csv.write_text(_module_csv(report.module_metrics), encoding="utf-8")
produced["module_csv"] = str(module_csv)
func_csv = out / "function_metrics.csv"
func_csv.write_text(_function_csv(report.function_metrics), encoding="utf-8")
produced["function_csv"] = str(func_csv)
summary_path = out / "summary.txt"
summary_path.write_text(_summary_text(report), encoding="utf-8")
produced["summary"] = str(summary_path)
# Charts (optional)
try:
import matplotlib.pyplot as plt # noqa: F401
_write_charts(report, out)
produced["charts_dir"] = str(out / "charts")
except Exception:
pass
return produced