

SBCCC Search and Citation Graph
SBCCC Search & Graph: What I Learned Shipping a Multi-Agent Q&A Service.
A working notebook on retrieval, citation graphs, Shepardizing for AI, and why asking users to tune sliders is the wrong answer.
I shipped something this week that takes five LLM calls to answer one question. That seems wrong until you look at the question.
The problem: North Carolina's community college system runs on regulatory code, split across two intertwined documents. The State Board of Community Colleges Code (SBCCC) and General Statutes Chapter 115D.
SBCCC sections often end with a "History Note" that cites the G.S. 115D section it derives authority from:
History Note: Authority G.S. 115D-5; G.S. 115D-12; Eff. June 1, 2022; Amended Eff. March 1, 2024.
Real questions live across both documents. "How can student fees be spent?" requires finding the SBCCC sections that allow specific fee types, then walking from each one into 115D to find the underlying statutory authority. "What's the basis for the IT security program?" requires the same kind of cross-corpus traversal. Answer either one with just SBCCC and you've cited rules without their source. Answer with just 115D and you have authority without operational detail.
The simple version of this is "a chatbot with RAG." I built that first. It was wrong often enough to be useless. Here is what shipping the production version actually taught me.
The simple version, and why it failed
Retrieval-augmented generation is the default tool for this shape of problem. Embed the corpus, embed the question, return the top-K most similar chunks, hand them to an LLM, render an answer. Fast to build, recognizable to anyone who's read an AI tutorial in the last two years.
It works for some questions. It fails on questions where the right answer is more than the top-K relevant sections.
Here's the failure pattern: a user asks "tell me everything about excess fees." Vector retrieval returns the top 10 sections containing the words "excess" and "fees." The LLM synthesizes a clean-looking answer citing those 10 sections. The answer omits §1H-SBCCC-300.1 — Excess Receipts of Educational Activities, because that section uses the word "receipts" not "fees" and ranks 14th in the retrieved set. The user has no way to know they got an incomplete answer. The system has no way to know either.
This isn't a hypothetical. The query that surfaced this miss came from a real user in early May, and §1H-SBCCC-300.1 is exactly the section a user would want to see when thinking about how to deploy excess fee balances.
The hard distinction is this: vector retrieval can rank sections by relevance to a question. It cannot reason about completeness — whether the set of returned sections, taken together, is sufficient to answer the question correctly.
That's the problem the production version had to solve.
What I built instead
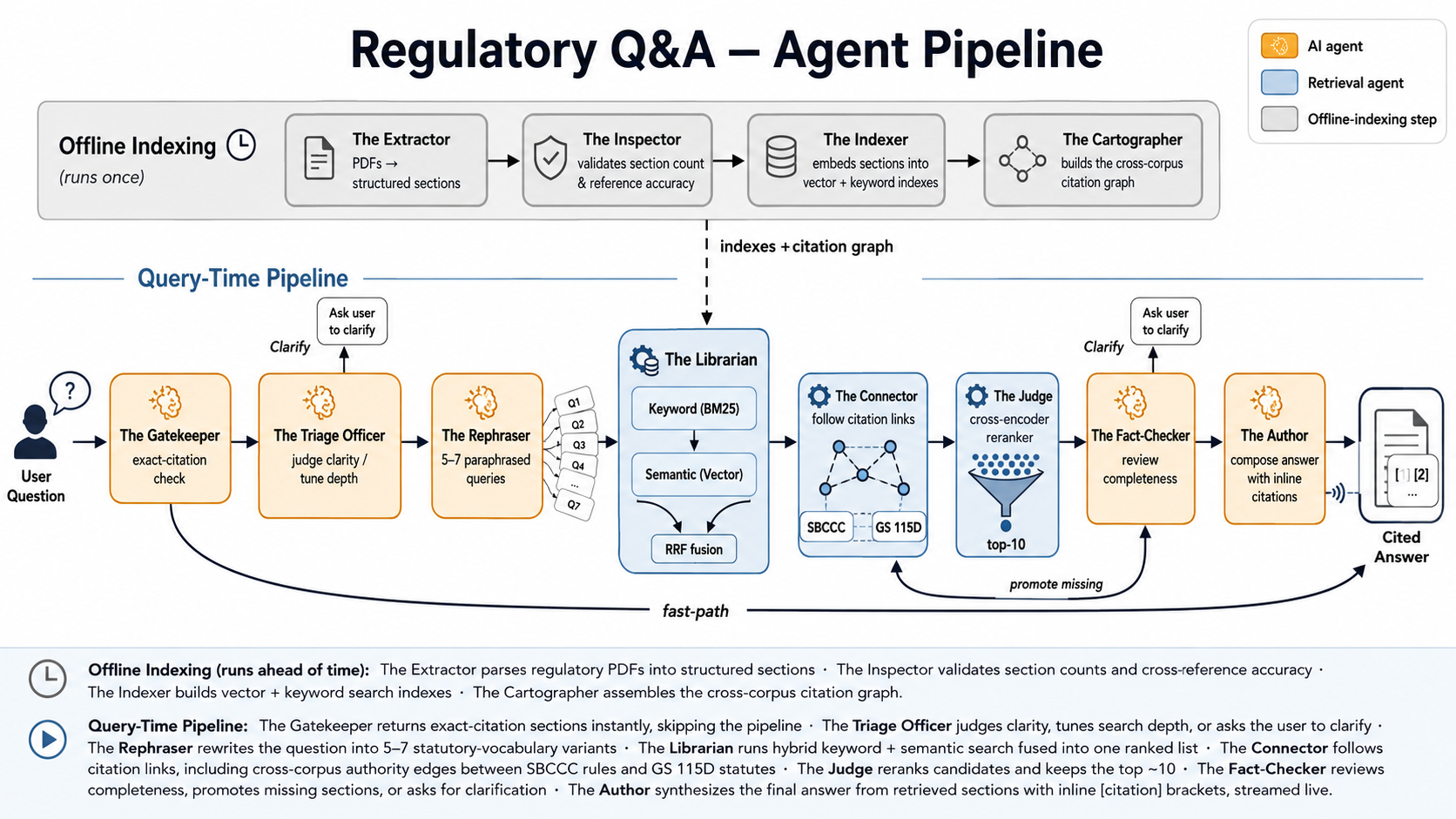
The shipped architecture is five LLM calls in sequence, each with one specific job, plus an asynchronous feedback loop that turns answer-misses into permanent regression tests. In order:
Agent 1 — Triage. Sees the query and a catalog of the corpus's subchapters. Decides whether the question is clear (well-formed, answerable with retrieval) or needs clarification (vague enough that returning a coarse answer would waste compute and confuse the user). If clear, recommends retrieval parameters: how many candidates to pull, whether to trace citations, how deep, how permissive the relevance threshold should be.
Agent 2 — Query expansion. Takes the natural-language question and rewrites it into 3–5 paraphrases that match the statutory voice — "X is established," "X shall consist of," "X is authorized to." The corpus is written in this voice; user questions are not. Bridging the language gap upstream of retrieval beats fixing it downstream.
Retrieval engine. Hybrid: BM25 for lexical match, dense embeddings (BGE) for semantic match, fused by Reciprocal Rank Fusion, then reranked by a cross-encoder. After ranking, walks the citation graph bidirectionally from the top candidates — following both what each section cites (out-edges, the doctrinal lineage) and what cites each section (in-edges, how the rule is applied elsewhere). This is the "graph" part of "Search and Graph," and the most consequential design decision in the whole stack. More on it below.
Agent 3 — Retrieval review. Sees the question, the candidate sections retrieved, and a prompt-cached catalog of the full corpus. Asks: did the retrieval miss anything material? If yes, force-include up to 3 missing IDs into the synthesis context. If the candidate set itself reveals ambiguity the triage missed, short-circuits with clarification chips.
Agent 4 — Synthesis. Renders the answer. Cites sections by ID. Quotes verbatim where exactness matters; paraphrases where it doesn't. Refuses to invent citations.
Agent 5 — Completeness critic. Async, post-answer. A second pass that sees the question, the rendered answer, the retrieved IDs, and the corpus catalog. Returns complete or likely_incomplete plus up to 6 missing sections with one-line "why" notes. Every likely_incomplete verdict gets persisted to disk. A routine review promotes accepted misses to a regression-gold file. The next eval run reads that file. Production misses become permanent test cases the build cannot regress past.
End-to-end: 5–10 seconds for vague queries (chips returned without paying for retrieval), 60–80 seconds for clear queries (four Sonnet calls plus retrieval plus rerank).
The Shepardizing problem
The citation-graph walk is the most distinctive piece of this architecture, and the part I want to spend the most time on. Because it turns out the question "when have I traced enough citations?" is not a new question — it's a 100-year-old question in legal research.
Shepard's Citations, founded in 1873 and now operating as Shepard's Citations Service inside LexisNexis, exists specifically to answer this question for lawyers. The verb form — "to Shepardize a case" — means walking forward and backward through the citation graph from a case to determine whether the case is still good law, what later authorities have said about it, and what authorities it relied on. Lawyers have been doing this for over a century. The discipline has accumulated norms that the IR-side citation-graph literature has not.
Three of those norms shaped the algorithm I shipped:
1. The 20-citing-authorities rule of thumb. Practitioners using Shepard's or KeyCite typically review up to about 20 citing authorities per source before stopping. Beyond that, further citations rarely add new propositions — they just restate ones already covered. The shipped /regulatory/neighbors endpoint enforces this with cap_per_source = 20 as the default. A reviewer who wants to broaden recall can override; most don't need to.
2. Forward and backward tracing serve different purposes. Backward tracing (what the source cites) tells you the doctrinal lineage — where the rule comes from, what conditions it depends on, what definitions it relies on. Forward tracing (who later cited the source) tells you how the rule has been applied, narrowed, or expanded. The bidirectional walk through out_edges plus in_edges corresponds directly to this distinction. Both are needed; one without the other produces lopsided answers.
3. The materiality stopping test. Lawyers stop tracing citations when the next citation is not load-bearing for a contested point. Synthesized from a Stanford research-problem PDF I read while designing the algorithm: stop when the next citation doesn't materially change the answer. This is what the Completeness Critic implements — it doesn't flag every section that touches the topic. It only flags missing sections that materially change the answer.
There was also a meaningful debt to the IR-side literature on adaptive depth control. Two specific ideas got shipped:
Hub-aware adaptive depth. Some sections in this corpus are citation hubs — §115D-5 is cited 246 times, by far the most-cited node. Walking through the hubs explodes the result set without adding signal. The shipped algorithm uses an in-degree threshold (max(10, top 2%)) to block recursion through super-hubs while still including them at hop 1. This idea comes from a paper on hub-aware citation tracing; the threshold floor of 10 prevents the corpus's heavy skew from collapsing the cutoff to something useless.
Iterative refinement from residuals. After retrieval, sample real citing authorities that didn't make it into the retrieved set. The residuals are structured signal, not noise. Once the miss rate between depth N and depth N+1 drops below tolerance, that's your cutoff. The critic-flag → regression-gold loop is exactly this idea, implemented in production: real production residuals accumulate, get reviewed, and the ones that should have been caught become permanent eval cases.
Without these norms shaping the defaults, the natural settings — depth 3, no per-source cap, no relevance gate, no hub throttle — produce roughly 150 results per cited section on this corpus. Useless. The Shepardizing literature didn't give me the algorithms; the IR literature did. But the IR literature didn't give me the norms — the lived experience of "how much is enough." Combining them produced the shipped defaults: per-source cap of 20, relevance gate at hop 2 and beyond, hub throttle on genuine super-hubs only, bidirectional traversal.
The other hard insight: sliders are the wrong UX
The first production version exposed knobs. top_k, trace depth, similarity threshold τ, on/off for graph expansion. Power users could tune. Reasonable approach. Recognizable from any IR tool ever shipped. It failed quietly. Here's how I noticed.
A user filed a complaint that the system had missed §1H-SBCCC-300.3 — "Excess bookstore revenues" — on a query about excess fees. They had cranked top_k to 20 and depth to 3, the highest values the UI offered. The system still missed it. They had no way to know why, and no way to fix it.
The insight: the user was searching because they didn't know the answer. They couldn't tell whether the system had missed something. Asking them to tune sliders to fix recall was asking them to do a job only the system itself could do.
The fix was to move the parameter decisions from the user to the triage agent. The user sliders are still there, but they default to "auto" — populated per-query by the triage agent's recommendations. Touching a slider switches it to "manual" (yellow pill) and that value persists across subsequent queries until the user clicks the pill to reset. A user who never touches a knob gets per-query-tuned retrieval. A power user who wants to override always can.
The architectural lesson generalizes beyond this project. Anywhere a tool exposes parameters that a non-expert user couldn't reasonably tune correctly, those parameters should be controlled by a system component that can reason about them. The user's job is to ask the question. The system's job is everything between question and answer.
The trust loop
The most operationally important piece of this stack borrows a discipline from software engineering: bug-driven testing.
In unit-testing practice, when you find a bug, you write a test that fails because of the bug, then fix the code, then watch the test pass. The test stays in the suite. The build cannot regress past that bug. In retrieval, the equivalent is: when the system gives a wrong or incomplete answer, capture the query plus the correct expected sections, add it to the eval set, and gate future deploys on the result. Production misses become permanent regression cases.
The shipped implementation:
The Completeness Critic writes every likely_incomplete verdict to eval/results/critic_flags.jsonl. One line per flag.
A CLI reviews flags interactively. For each flag, the reviewer sees the question, the original answer, the missing sections the critic proposed, and an option to accept, reject, or modify before promoting.
Accepted flags move to eval/regression_gold.jsonl — the regression test set.
The eval runner loads regression cases automatically. The --regression-gate <threshold> flag exits non-zero if mean recall on regression cases drops below threshold.
Deploys gate on the regression eval. A change that improves average retrieval but regresses on previously-fixed cases gets caught.
This loop is the answer to the question "how do I know my LLM-powered product is getting better and not worse over time?" Without it, deploys are vibes. With it, deploys are bounded by evidence.
I want to be honest about what this loop doesn't do. It doesn't catch silent quality drift that the critic agent itself misses — if the critic gets worse at noticing missing sections, the regression set stops growing in places it should. The mitigation is occasional sampling of user queries that the critic marked complete, hand-reviewed to verify that "complete" still means complete. So far, on the order of 50 queries reviewed; no silent failures detected. The discipline matters as much as the architecture.
Cost discipline as architecture
We set a cost target for the steady-state and stayed under it. The trick wasn't picking a cheap model. It was picking the right model per step:
Haiku 4.5 for the early-stage classifier work where the answer space is small and deterministic.
Sonnet 4.6 for triage, query expansion, retrieval review, synthesis, and the completeness critic — anywhere reasoning matters.
Opus 4.7 with adaptive thinking enabled, for the LLM-as-judge in eval runs only. The judge needs to be smarter than the synthesizer it's judging. But the judge runs offline against gold-set queries, not on every user query, so the cost is bounded.
Most queries don't trigger every agent. A query the triage marks vague short-circuits to clarification chips and never pays for retrieval, synthesis, or critic. A query the retrieval review finds clean doesn't pay for force-includes. The system pays full price only for hard queries — which is also where the full price is justified.
The full stack: Python 3, Flask, sentence-transformers (BGE for dense embeddings), rank-bm25 for sparse, a cross-encoder for rerank, Claude (Haiku 4.5 + Sonnet 4.6 + Opus 4.7), nginx fronting Flask processes for the regulatory service, deployed on a Google Compute Engine VM.
What this generalizes to
I built this on regulatory code because that's the corpus that was in front of me, but the architecture isn't about regulation. It's about any corpus where:
Answers require completeness, not just relevance — leaving out a section produces a wrong answer, not just a less-good one.
Sections cite each other, and the citation graph carries semantic weight that a vector index misses.
The user is searching because they don't know the answer, so the system cannot rely on the user to evaluate its own output.
Three other corpora that fit this shape: tax code and regulatory rulings; standards documents (GAAP, GASB, IFRS); contract families that share definitional clauses across many instruments. In each case, the cost of an incomplete answer is high enough that the agent-pipeline overhead is justified. In each case, the citation structure is dense enough that a graph walk adds real signal. In each case, the user doesn't know what they don't know.
The cost discipline matters too. A per-query stack is something a small department or a single advisor can deploy and maintain. The architecture and the cost target shaped each other throughout this build.
What's next
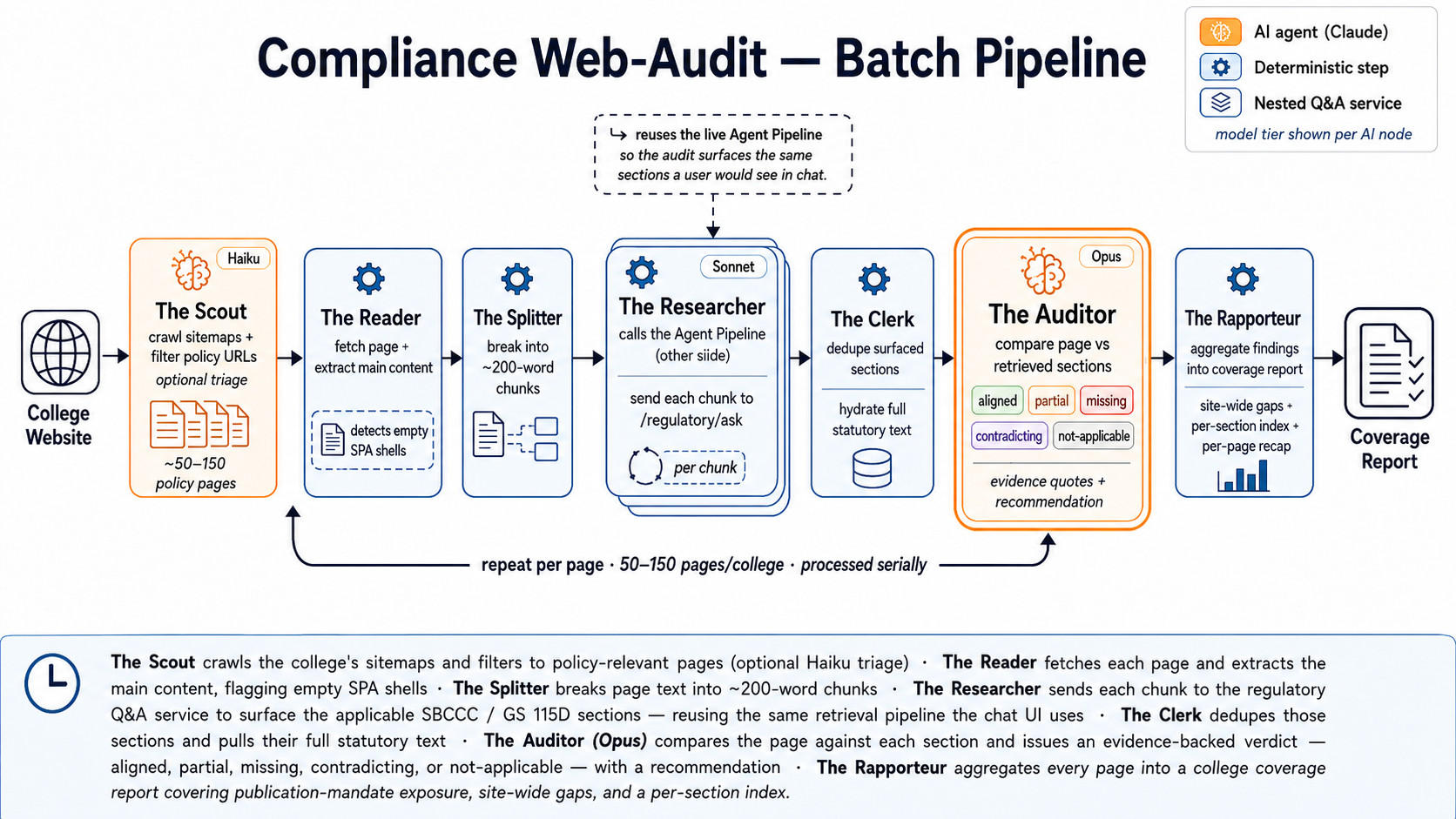
The next service in this stack is a compliance review tool, currently shipping in pieces. Same retrieval backend, opposite input shape: instead of "what does SBCCC say about X?" (the user asks the question), the compliance tool takes a college's public web page as input and asks "does this page accurately reflect what SBCCC says about X?" (the user supplies the answer, the tool audits it). Phase 13.1 (single-page advisor) is in production and has been validated against an 8-webpage set with all reviewed findings accepted. Phases 13.2 (cross-page aggregator) and 13.3 (sitemap crawler with Haiku triage) may ship this week. First multi-college test audits are underway.
— Bruce Cole, May 2026
Update
The compliance tool build is complete. Here is a peek at the underlying agent workflow. Please contact me to discuss training on other regulatory bodies and reviewing other sites.
Bruce is a higher-education finance leader and CPA with an A.A.S. in Artificial Intelligence from Central Piedmont Community College. He writes about finance, AI, and the design of decision-support systems at caterbum.com.