

AI as Flashlight, Not Scalpel: Rethinking How We Use Today’s LLMs
Most of the frustration around large language models comes from asking them to be something they’re not.
We point them at a task that feels like surgery—precise, high-stakes, tightly constrained—and then discover we have to supervise every move, validate every output, and correct subtle errors. At that point, the “AI assistant” feels more like an intern you can’t trust than a tool that saves time.
The problem isn’t just the models. It’s the metaphor.
Today’s LLMs are not scalpels. They are flashlights.
When you treat them like a scalpel—expecting exactness, reliability, and repeatable precision—you put them in the worst possible role. When you treat them like a flashlight—expecting breadth, exploration, and illumination—you unlock most of their actual value.
This post is an argument for that shift in mindset, using a concrete example from a project I call “CaterShompas.”
The Scalpel Illusion
A scalpel does one thing very well: it cuts exactly where you tell it to, in exactly the way you expect. To use an LLM like a scalpel is to say:
“Write this legal clause exactly right.”
“Summarize this document with zero omissions or misinterpretations.”
“Generate production-ready code I can deploy without review.”
Sometimes models can do surprisingly well at these. But as a default use case, this is fragile:
You must verify everything.
If the task is high-stakes, you still have to read the legal clause, audit the summary, and review the code. The more precise the requirement, the more time you spend checking.You get “plausible wrongness.”
LLMs rarely fail loudly. They fail smoothly. They produce content that looks right and sounds right—until you notice the missing assumption or incorrect detail.The cost-benefit is weak.
If you spend as much time validating the output as you would have spent doing it yourself, you don’t have a tool—you have noise.
In that mode, the LLM is like a scalpel with a shaky hand. You can’t relax, you can’t delegate, and you can’t really trust it with anything critical.
LLM as Flashlight
A flashlight doesn’t need to be precise. It doesn’t need to be perfect. Its job is to reveal what’s in the room so you can decide what to do next.
Used as a flashlight, an LLM shines in tasks like:
Surfacing concepts, features, or angles you wouldn’t have thought of on your own.
Mapping a messy, ambiguous input into a structured but exploratory representation.
Helping you sense the landscape so humans can make the actual decisions.
Here, the bar for “good enough” is very different:
It’s fine if 10–20% of the ideas are off base or strange.
It’s fine if some suggestions are redundant.
It’s fine if there are “goofy” elements, as long as the overall space is richer than what you started with.
The evaluation question changes from: “Is every detail correct?” to “Did this help me see more of the space, faster?”
That’s a much better fit for what current LLMs reliably do.
A Concrete Example: “CaterShompas” as Flashlight
Consider a shopping workflow—I’ll use the Caterbum shopping compass project as a concrete illustration of the flashlight model.
Step 1: User Input → Commodity Code
The process starts with a very human input:

This is not a SKU. It’s not a spec sheet. It’s an utterance—a mix of intent, preferences, and vague language.
Behind the scenes:
The utterance goes into a small RAG/LLM pipeline.
The system assigns it to a commodity code (for example, an UNSPSC code for “cat toys).
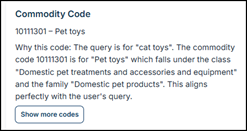
3. The system now has:
The original user utterance.
The commodity code.
The commodity code’s description
No scalpels so far. Just classification and mapping.
Step 2: Flashlight Mode – Feature Discovery
Next comes the flashlight moment.
We send the utterance and the commodity code description to an LLM with an instruction like: “Return a list of features someone might care about for this kind of item.”
The model returns features like these:

Are all of these perfect? No. Does Animal: Cat as a feature make sense? No. But play style, toy type, and feature provoke buyer reflection about what they want.
You might see a few odd or redundant entries:
“Animal”
“Color” (Doesn’t red look like gray to cats?)
But that’s acceptable, because we’re in flashlight mode. The goal isn’t precision. The goal is coverage and idea generation:
The user may never have thought about play style.
They may realize they care more about material than they initially understood.
They might decide they don’t care about size at all.
The LLM has illuminated the room. It has turned an unstructured desire (“cat toys”) into a menu of possibilities.
Step 3: Human Filtering and Preference Setting
Now the human takes over.
They browse the feature list.
They select what actually matters:
Must have: interactive, crinkle sound.
Don’t care: Size, number of toys.
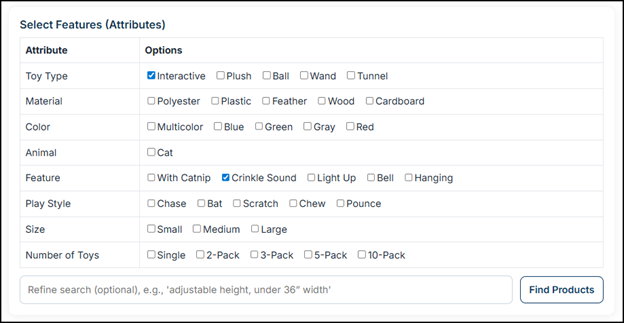
Any “goofy” features are simply ignored. They don’t harm the process, because they are not being treated as authoritative facts. They’re just items on a menu the user can decline.
The LLM is not deciding. The human is.
Step 4: Structured Search – From Utterance to Shopping List
Only after the preferences are set do we bring in something more like a “scalpel”—but notice that it’s the shopping engine, not the LLM.
We send:
The original user utterance.
The mapped commodity code.
The selected features.
to a system that returns:
A list of products.
With filters already applied.
That reflect not just the original vague intent, but also the clarified feature preferences.

The high value of the process is not that AI picked the “perfect” toy. It’s that:
It compressed the exploration phase, and
It expanded the option space with features the user hadn’t considered,
While still leaving judgment and final choice with the human.
That’s a flashlight workflow, end-to-end.
Why This Is High-Value Use of Today’s LLMs
Several things make this pattern a good match for current models:
Error-tolerant stage.
The model operates in a space where small errors are cheap. A silly feature suggestion doesn’t break anything. It just gets ignored.Human-in-the-loop by design.
The workflow explicitly depends on user judgment:Users choose which features matter.
Users review the final product list.
Amplified discovery, not automated decision.
The main gain is better discovery:Users see more dimensions of the decision.
They move from “I want a cat toy” to “I want an interactive, crinkle sound toy” in a few clicks.
Separation of concerns.
The LLM is responsible for ideas and structure (features, attributes, interpretations).
The shopping or rules engine is responsible for precision (filters, inventory, pricing).
General Design Principles: Building Flashlight-First AI
The “CaterShompas” example generalizes. When designing with LLMs today, aim for patterns like:
Keep critical correctness downstream.
Use traditional systems (databases, rules engines, deterministic code) to enforce constraints.
Treat the LLM as a front-end sense-making layer, not a source of truth.
Design for user selection, not blind automation.
Let users pick from model-generated options.
Make it easy to discard or override suggestions.
Judge success by “better decisions faster,” not perfection.
The right metrics for flashlight use cases are:Time to insight.
Breadth of options considered.
User satisfaction with the final decision.
Not: “Did the model get it exactly right on the first try?”Make weirdness survivable.
Assume some outputs will be off. The design should expect this and make it harmless:Optional, not mandatory, use of model outputs.
Interfaces that invite editing and filtering.
Where Scalpels Still Matter
None of this means you should never use LLMs in precise roles. It means:
If you do, you must surround them with guardrails, validation, and strong constraints.
You should be realistic about the verification cost.
You should be selective: reserve “scalpel” expectations for narrow, well-understood tasks, often combined with tools (code execution, retrieval, rules).
But for most everyday work—exploring ideas, framing problems, mapping unstructured input to structured options—the flashlight pattern is the safer, more productive default.
Conclusion
Today’s LLMs are extraordinarily good at shining light into messy spaces.
They help you see more of the room: possibilities, features, trade-offs, questions you didn’t think to ask. When you use them this way—as flashlights, not scalpels—you don’t need them to be perfect. You need them to be illuminating.
The “CaterShompas” workflow is one concrete example: starting from a vague utterance, letting the LLM illuminate a feature space, then letting the human choose what matters before a more precise system fetches products. The goofy suggestions don’t matter. The additional, relevant ones do.
If you stop demanding surgical precision from a tool that’s built for illumination, you get less frustration—and more value.
The practical design question, then, is simple:
Where in my workflow do I need a scalpel—and where would a flashlight actually serve me better?
Most of the time, today’s LLMs belong in the second category.